

在前端性能优化的世界里,我们常听到这样的抱怨:“页面感觉有点卡”、“图片加载好慢”。然而,“感觉”是主观的,也是无法被优化的。作为前端工程师或性能专项负责人,我们的核心任务是将这些模糊的体感转化为精确的数据,进而驱动治理。
「资源性能」专题正是为此而生。它不再局限于关注页面整体的 Load 时间,而是深入微观,回答四个关键问题:当前资源加载总成本是否可控?是哪一类资源拖慢了页面?慢是网络链路问题还是资源本身过大?缓存策略是否真正生效?
本文将带你走进「资源性能」的实战世界,看如何通过数据分层,将资源性能问题从“黑盒”变成“白盒”。
一、总览:建立资源成本的“健康仪表盘”
当我们进入「资源性能」的 overview(概览)页面时,首先映入眼帘的不应是繁杂的曲线,而是能够一锤定音的核心指标。这是判断系统资源健康度的第一道关卡。

在资源治理中,我们关注以下核心指标:采样量、平均加载耗时、总传输流量、加载成功率。但在这里,我要特别强调一个常被忽视的 KPI——缓存命中率。
很多团队只关注资源加载是否成功,却忽略了“是否高效加载”。一个健康的资源体系,其静态资源(js/css/img)的缓存命中率应当维持在极高水平。如果总览数据显示平均加载耗时上升,同时缓存命中率大幅下降,这通常比单纯的“慢”更可怕——它意味着你的 CDN 策略失效了,或者发布流程中出现了文件名 Hash 变动导致的缓存击穿。
将“缓存命中率”作为资源治理的 KPI,而不仅仅是一个观察指标,是思维转变的第一步。它直接关联到用户的带宽成本和加载速度。
二、趋势图:定位“什么时候开始坏”
当总览指标亮起红灯,我们需要迅速定位问题的时间窗口。trendChart(趋势图)组件提供了加载时间与文件大小的双 Tab 视图,配合资源类型筛选,是排查问题的利器。

在实际操作中,我们常遇到这样的场景:页面整体加载时间在某天突然飙升。通过趋势图,我们可以将资源类型筛选为“script”或“img”,观察不同时间段的曲线变化。
如果“script”类的平均文件大小在某个版本发布后突然翻倍,那么问题很可能出在构建配置上,比如误引入了巨大的第三方库,或者 Tree Shaking 失效。如果“图片”类的加载耗时在某个营销活动开始后呈锯齿状上升,那么大概率是运营上传了未压缩的高清原图。
趋势图的价值在于“关联”。通过将时间轴与发布记录、活动上线时间进行对齐,我们可以快速判断是代码变更导致的退化,还是内容变更引发的波动。
三、分布区:圈定“嫌疑范围”
知道了“什么时候”出问题,接下来要解决的是“哪里”出问题。distribution(分布区)通过资源类型占比和耗时区间分布,帮助我们圈定嫌疑目标。

这里有两个维度的分布至关重要:「资源类型占比」它直观地展示了 script、link、img等各类资源在总请求数或总流量中的比例。如果图片资源占比异常高,治理方向自然指向图片优化。「耗时区间分布」这是一个柱状图,展示了多少资源是在 0-200ms 加载完成的,又有多少资源耗时超过了 2s。
在排查问题时,如果发现耗时区间向高区间(如 >2s)显著偏移,说明这不是个别用户的网络波动,而是普遍存在的资源加载瓶颈。此时,我们可以从图表模式切换到列表模式,直接查看那些落在“高耗时区间”的资源样本,为下一步的精准归因做准备。
四、列表与详情:资源级的“精准归因”
这是「资源性能」最核心的部分。通过 resourceList(资源列表)和 resourceDetail(资源详情),我们终于可以从“宏观统计”下沉到“微观个体”。
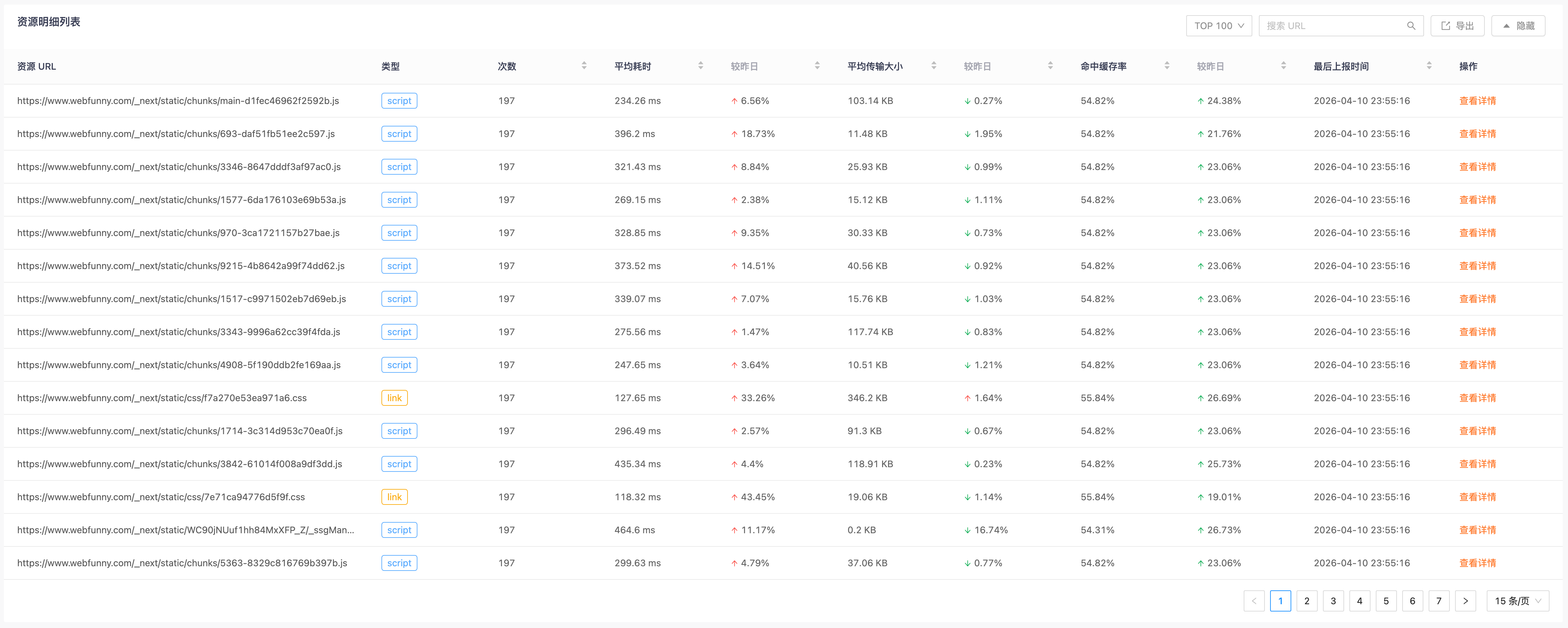
在资源列表中,我们支持 TOP N 排序、URL 过滤和分页。你可以轻松找出“加载最慢的前 10 张图片”或“体积最大的 5 个JS文件”。但这还不够,点击某个具体资源进入详情页,真正的“手术刀式”分析才刚刚开始。
资源详情中的核心是瀑布阶段分析。一个资源的加载过程被拆解为 DNS 查询、TCP 连接、SSL 握手、TTFB(首字节时间)和 Content Download(内容下载)。
- 如果 DNS/TCP 阶段耗时过长,说明是网络链路问题,可能需要优化域名解析或建立长连接。
- 如果 TTFB 耗时过长,说明服务端处理慢,或者 CDN 回源慢,需要排查后端接口或边缘节点。
- 如果 Content Download 阶段耗时过长,说明资源文件本身太大了,这是最直接的优化点——压缩、转码或裁剪。
此外,详情页通常支持“日志跳转”。如果某个资源加载失败或极慢,我们可以直接关联到该用户的 Session 日志,复现当时的操作路径,彻底还原案发现场。
五、地域趋势:判断“是否环境相关”
最后,我们不能忽视环境因素。regionalTrend(地域趋势)组件支持中国/全球切换,展示不同地域的采样量和平均耗时。
有些性能问题是“全局性”的,比如核心库升级导致的包体积膨胀,这会在所有地域的曲线上同步体现。但有些问题是“地域性”的,比如某省份的运营商 DNS 劫持,或者某个海外节点的 CDN 故障。
通过地域趋势图,如果发现只有特定区域(如西北地区或东南亚)的加载耗时飙升,而其他地区正常,我们就能迅速排除代码逻辑问题,转而联系 CDN 厂商排查节点状态,避免在错误的方向上浪费研发人力。
六、实战案例:图片资源导致首页加载抖动
为了更直观地展示「资源性能」的治理价值,我们来看一个真实的案例:某电商平台首页在大型活动期间出现明显的加载抖动。
- 总览发现异常:监控大盘显示,首页平均加载耗时从 1.5s 上升至 3.2s,同时静态资源缓存命中率从 95% 跌至 60%。
- 趋势图定位:在趋势图中将资源类型筛选为“img”,发现图片加载耗时在活动上线时刻(10:00)呈断崖式上升。
- 分布图确认:耗时分布图显示,大量图片资源的加载时间集中在 2s-4s 区间,且主要集中在新上线的活动板块。
- 列表锁定目标:进入资源列表,按 URL 过滤活动图片路径,发现若干张 Banner 图和商品图的体积竟然超过了 2MB。
- 详情归因:查看具体图片的瀑布流,发现 DNS、TCP 阶段均正常,但 Content Download 阶段耗时极长。这证实了是文件体积过大导致的传输慢,而非网络链路问题。
- 治理动作:确认问题后,团队立即执行了图片压缩策略,开启 WebP/AVIF 自适应转码,并修正了 CDN 的缓存过期时间。半小时后,各项指标恢复正常。
这个案例清晰地展示了「资源性能」的优势:它把模糊的“慢”,拆解成了类型(图片)、体积(过大)、阶段(Content Download)、地域(全局)四个可执行的维度。
结语
「资源性能」的价值不在于告诉我们“有没有慢资源”,而在于能否把“慢资源”转化为一份可落地的优化清单。当你能明确是哪类资源、哪个阶段、哪些 URL、哪些区域出现问题时,性能优化就不再是拍脑袋的经验驱动,而是精准的数据驱动。从总览到详情,从趋势到分布,这套体系让资源性能治理变得有迹可循,让每一字节的传输都物超所值。
