
在前端性能治理的深水区,我们常常面临这样的困境:监控大盘显示“平均加载时间”正常,但用户投诉却此起彼伏;或者知道某个页面慢,却无从下手,是在网络层、资源层还是渲染层?传统的“看均值、猜原因”的粗放式优化已无法满足现代 Web 应用对极致体验的追求。
「页面性能 」正是为了解决这一痛点而生。它不仅仅是一个数据展示面板,更是一套从宏观感知到微观定位,再到行动验证的完整分析闭环。本文将结合真实监控场景,拆解如何利用「页面性能 」将“页面慢”这个模糊的主观感受,转化为可度量、可定位、可修复的具体工程问题。
1. 先看总览:全局是否退化?
一切分析的起点,在于确认问题的存在性与严重性。进入「页面性能 」的「概览」模块,我们首先关注的是核心指标卡片。
在这里,采样 PV 告诉我们数据的置信度,而 首字节 (TTFB)、DOM Ready 和 页面完全加载 则构成了性能的铁三角。但最具业务价值的指标往往是 秒开率。
值得注意的是,「页面性能 」允许我们动态切换秒开的阈值(如 1s/2s/3s/5s)。这绝非一个简单的 UI 交互细节,而是对不同业务场景的尊重:
- 工具类/搜索类页面:用户期望即时响应,标准应设定在 1s - 2s。
- 内容阅读/电商详情页:用户容忍度稍高,3s 可能是更合理的及格线。
- 复杂后台管理系统:5s 内完成加载或许即可接受。
通过观察“较昨日”的涨跌趋势(如图中红色/绿色箭头),我们可以迅速判断系统整体健康度。如果秒开率突然下跌,即使平均耗时变化不大,也意味着长尾用户的体验正在恶化,必须立即介入。
2. 再看趋势:何时开始变差?
确认问题后,我们需要通过「性能趋势图」来锁定故障发生的时间窗口。
在这个视图中,我们不仅要看蓝色的平均加载耗时折线,更要关注橙色的采样 PV 柱状图以及隐含的百分位数据。避坑指南:均值陷阱
很多团队只关注平均耗时,但这极易掩盖真相。假设 90% 的用户加载只需 0.5s,但 10% 的用户因网络波动或设备老旧需要 10s,平均值可能依然维持在 1.4s 的“健康”水平,但那 10% 的用户实际上已经流失了。
因此,「页面性能 」强调结合快慢开占比(如 2 秒开率)进行分析。如果平均耗时平稳,但 2 秒开率大幅下降,说明系统的稳定性出现了问题,长尾效应加剧。此时,我们需要进一步下钻,找出是哪些特定时间段或特定群体导致了这种分化。
3. 用列表锁定问题 URL
全局视角只能告诉我们“病了”,而「页面性能列表」能告诉我们“病在哪里”。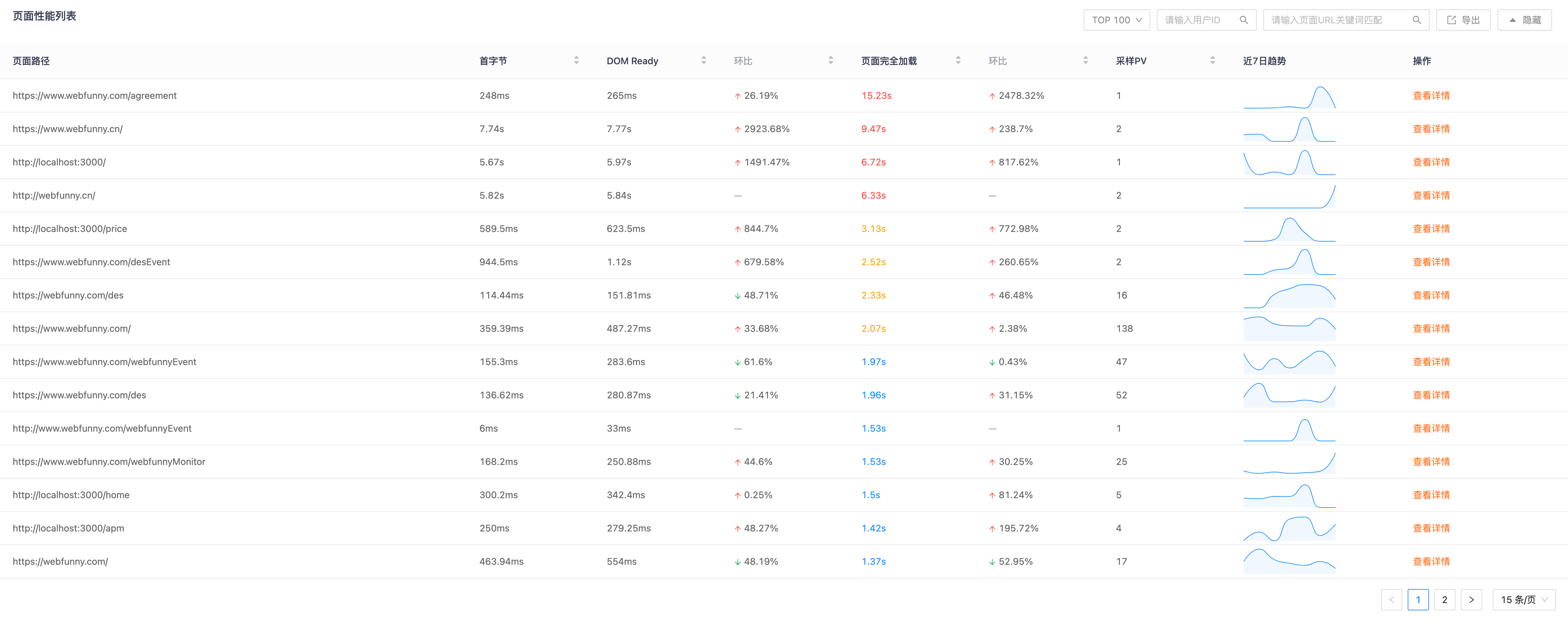
这是排查问题的核心战场。面对成百上千个页面路由,盲目查看是低效的。建议遵循以下排查路径:
- 按耗时排序:直接点击“页面完全加载”列头,让最慢的页面排在顶端。通常 Top 5 的慢页面贡献了 80% 的性能抱怨。
- 关键词过滤:如果你接到反馈说“活动页打不开”,直接在搜索框输入 /activity 或相关关键词,快速隔离问题范围。
- 对比昨日:重点关注“较昨日”涨幅最大的页面。一个平时 1s 加载的页面突然变成 3s,比一个常年 5s 的页面更值得警惕,因为这通常意味着近期代码变更引入了回归。
列表中提供的近 7 日趋势缩略图非常实用,它能让你在不进入详情的情况下,直观感受到该页面的性能波动形态(是持续慢,还是偶发抖动)。
4. 进入 URL 详情做深度下钻
锁定目标 URL(例如 https://webfunny.com/des)后,点击“查看详情”,我们进入了微观诊断室。这里是将“聚合数据”还原为“单条证据”的关键步骤。
4.1 瀑布图:时间的去向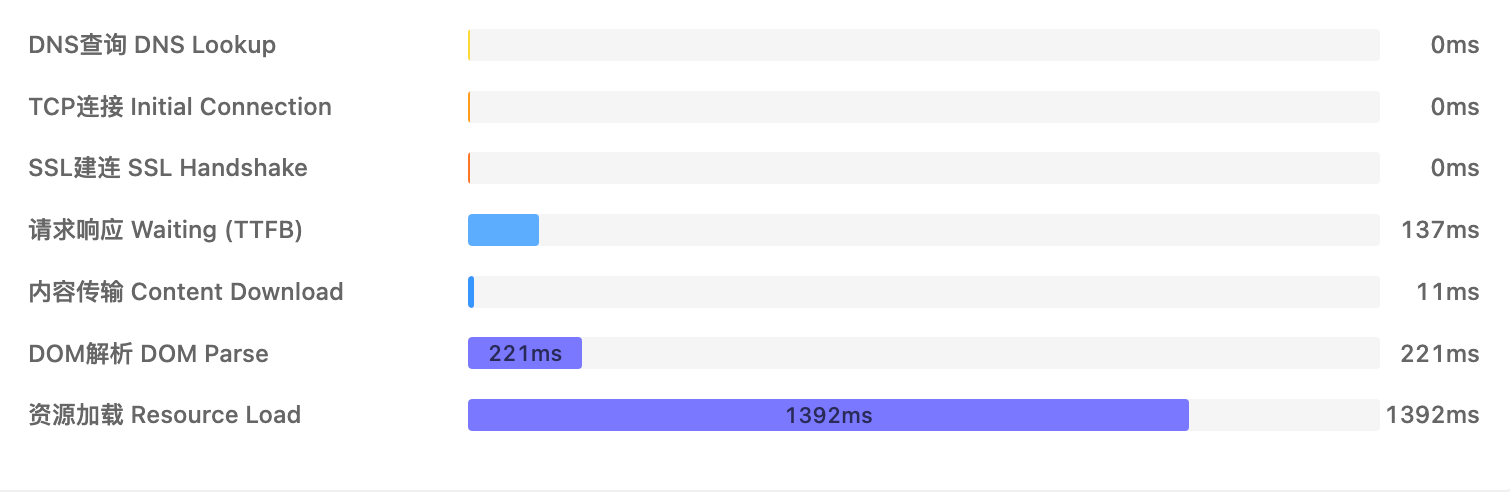
瀑布图清晰地展示了从 DNS 查询到资源加载完毕的全生命周期。
- DNS/TCP/SSL:耗时过长?可能是网络链路问题或服务器配置问题。
- TTFB (Waiting):首字节时间长?通常是后端接口处理慢或数据库查询慢。
- DOM Parse:解析时间长?可能是 HTML 结构过于复杂或 JS 阻塞了主线程。
- Resource Download:这是最常见的问题点。如图示案例中,紫色的“资源加载”条占据了绝大部分时间,说明瓶颈在于静态资源(图片、JS、CSS)的下载。
4.2 资源列表:谁在拖后腿?在详情页下方,「资源性能」列出了具体的资源加载列表。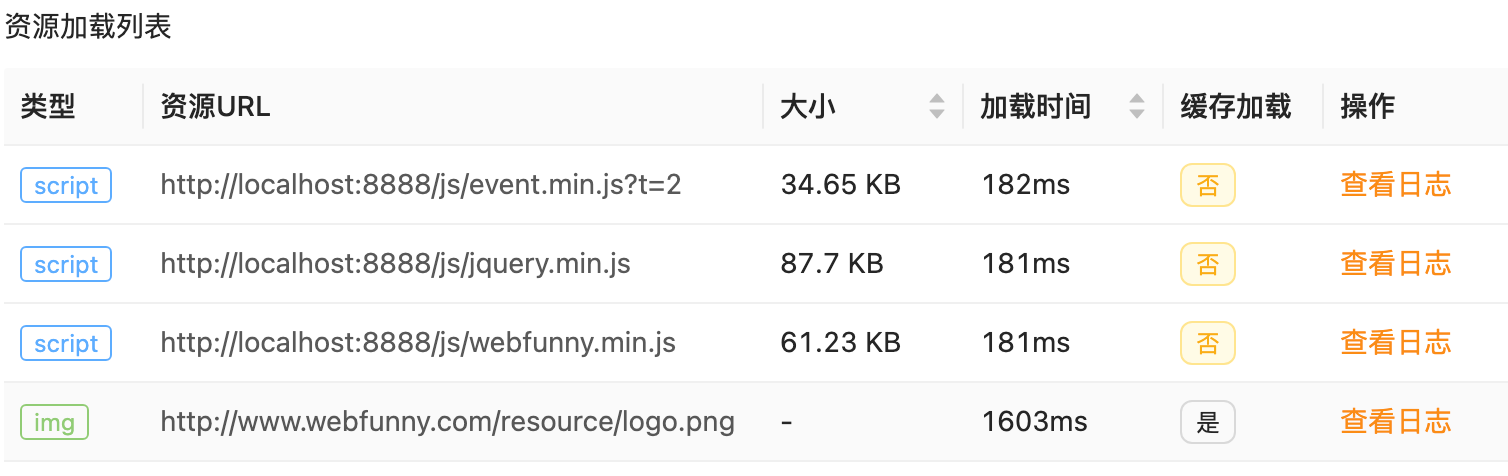
这里我们能精确看到每一个脚本、每一张图片的加载耗时和大小。
- 发现异常:某个 script 文件加载耗时 182ms,而另一个大图片耗时 1603ms。
- 缓存检查:注意“缓存加载”列。如果关键资源显示“否”,说明 CDN 缓存策略未生效,导致用户每次都要重新下载,极大影响二次访问速度。
- 日志跳转:点击“查看日志”,可以直接跳转到该次具体请求的原始日志,查看底层信息,实现从“指标”到“现场”的无缝衔接。
5. 用分布视角确认影响面
最后,我们需要回答一个问题:是个例还是普遍现象?这需要借助「地域分布」和其他维度图表。
- 地域维度:通过热力地图,我们发现某些省份(如四川、河南)的加载时间明显偏红(慢),而其他省份偏绿(快)。这可能暗示了 CDN 节点在这些区域的覆盖不足,或者当地运营商网络存在波动。
- 设备与环境:
- 操作系统/浏览器:是否仅在 iOS Safari 或旧版 Android 上慢?这指向兼容性问题。
- 网络类型:4G 用户是否显著慢于 WiFi 用户?如果是,可能需要针对弱网环境做资源降级策略。
- PV 分布直方图:观察加载耗时的分布形态。如果大部分集中在 0-1s,但有少量长尾分布在 10s+,说明是偶发的极端情况;如果分布均匀右移,则是整体架构问题。
关键案例复盘:活动页晚高峰“偶发慢开”
让我们将上述流程串联起来,复盘一个真实场景:
- 发现:周一早会,「页面性能 」在 概览 发现周日晚上 20:00-22:00 期间,全站 2 秒开率 从 85% 跌至 70%,但平均耗时仅上升 100ms。
- 定位:进入「性能趋势图」确认时间窗口,随后在「页面性能列表」中按时间过滤,发现 /campaign/spring-festival(春节活动页)的 P95 耗时飙升。
- 下钻:点击进入该 URL 详情。瀑布图显示,DNS 和 TTFB 正常,但 Resource Download 阶段出现大量长条。
- 归因:查看资源列表,发现一张大小为 2MB 的活动背景图加载极慢。进一步查看「地域分布」,发现慢请求主要集中在电信网络用户。
- 行动:
- 短期:紧急对该图片进行压缩,并强制刷新 CDN 缓存。
- 长期:检查电信线路的 CDN 回源策略,并在代码中增加图片懒加载和弱网提示。
- 验证:发布修复后,持续观察「页面性能 」,确认该页面的秒开率回升至正常水平。
结语
「页面性能 」的价值不在于绘制了多少精美的图表,而在于它构建了一套逻辑严密的推理链条。它将原本孤立的性能指标、URL 归因、资源链路、环境上下文和原始日志串联成一个闭环。
对于前端团队而言,拥有这样一个工具,意味着我们不再依赖用户的口头反馈来被动救火,而是能够主动洞察体验瓶颈,用数据驱动决策,将“页面慢”从一个模糊的抱怨,变成一个可被量化、可被定位、最终可被彻底解决的工程任务。这正是前端工程化走向成熟的标志。
